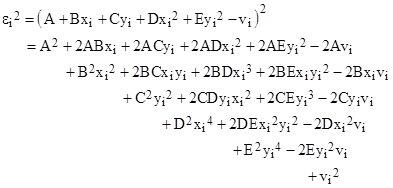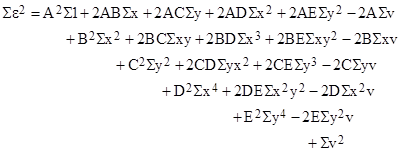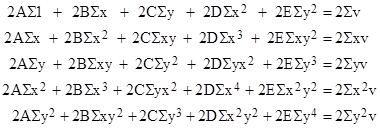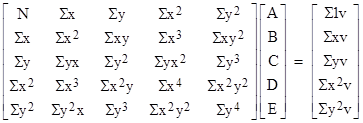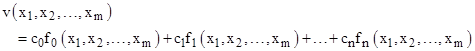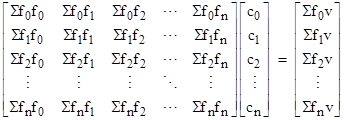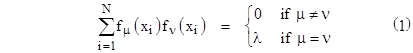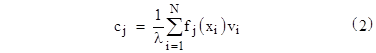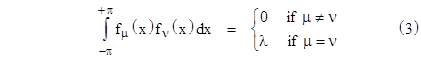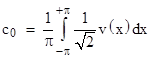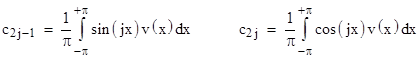|
Multiple Linear Regression and Fourier Series |
|
|
|
Suppose we have a large number of data points giving the value of some dependent variable v as a function of independent variables x and y, and we wish to perform a least-squares regression fit of the data to a function of the form |
|
|
|
|
|
|
|
This is called multiple linear regression, and can be applied to give the least-squares fit to any linear combination of functions of any number of variables. Our objective is to find the coefficients A, B, C, D, and E such that the sum of the squares of the errors between our model and the actual data points is a minimum. |
|
|
|
Consider the ith data point (xi,yi,vi), where vi is our dependent variable. For any given choice of coefficients A,B,..,E the square of the error εi for this data point is |
|
|
|
|
|
|
|
The squared error for each of the N data points is of this form, so we can add them all together to give the total sum-of-squares of all the errors. This yields an expression identical to the one above, except that xi is replaced by the sum of all the xi for i = 1 to N, and similarly yixi2 is replaced by the sum of yixi2 for i = 1 to N, and so on. Therefore, the sum of squares of the errors can be written as |
|
|
|
|
|
|
|
where the symbol Σ denotes summation of the indicated variables for all N data points. |
|
|
|
Now, to minimize the sum of squares of the errors, we can form the partial derivatives of the total sum of squares with respect to each coefficient A, B, ..., E in turn, and set each of these partial derivatives to zero to give the minimum sum of squares. Notice that, when evaluating the partial derivative with respect to A, only the terms in which A appears contribute to the result. Similarly the partial derivative with respect to any given coefficient involves only the terms in which that coefficient appears. Each of the partial derivatives turns out to be linear in the coefficients. For our example, setting each of the partial derivatives of the sum of squared errors to zero gives the following set of linear simultaneous equations |
|
|
|
|
|
|
|
Dividing all terms by 2, noting that Σ1 = N, and putting these equations into matrix form, we have the 5x5 system of equations |
|
|
|
|
|
|
|
We can solve this system by any convenient method (e.g., multiply the right-hand column vector by the inverse of the 5x5 matrix) to give the best fit coefficients A, B, C, D, and E. Thus the process of finding the optimum coefficients by multiple linear regression consists simply of computing all the summations Σ for the N data points, and then performing one matrix inversion and one matrix multiplication. |
|
|
|
Obviously this same method can be applied to find the constant coefficients c0, c1, .., cn that minimize the sum of squares of the error of any given set of data points v(x1, x2, …, xm) in accord with the model |
|
|
|
|
|
|
|
where f0, f1,.., fn are arbitrary functions of the independent variables x1, x2, …, xm. Proceeding exactly as before, we square the difference between the modeled value and the actual value of v for each data point, then sum these squared errors over all N data points, then form the partial derivatives of the resulting expression with respect to each of the n+1 coefficients, and then set these partial derivatives to zero to give a set of n+1 linear simultaneous equations which can be written in matrix form as |
|
|
|
|
|
|
|
where Sfifj signifies the sum of the products of fi(x1,..,xm) and fj(x1,..,xm) over all N data points. Multiplying the right-hand column vector by the inverse of the square matrix gives the least squares fit for the coefficients c0, c1, …, cn. So, in general, if we model the dependent variable v as a linear combination of n arbitrary functions of an arbitrary number of independent variables, we can find the combination that minimizes the sum of squares of the errors on a set of N (no less than n+1) data points by evaluating the inverse of a (n+1)x(n+1) matrix. |
|
|
|
Incidentally, the last equation shows that it is particularly easy to perform the regression if we choose basis functions fj that are mutually orthogonal, meaning that we have |
|
|
|
|
|
|
|
where “xi” here signifies all the independent variables for the ith data point. In this case the coefficient matrix in the system equation is diagonal, so the coefficients of our curve fit are simply 1/λ times the right hand column vector, which is to say, |
|
|
|
|
|
|
|
To illustrate this, suppose we have a sequence of equally spaced samples from a one-dimensional function v(x) over the range from x = –π to +π. With a large enough set of equally-spaced samples, the summation in (1) approaches an integration over the x variable, so our basis functions will be orthogonal if |
|
|
|
|
|
|
|
One such set of functions is the elementary trigonometric functions cos(kx) and sin(kx), so we can choose the following basis functions |
|
|
|
|
|
|
|
for j = 1 to infinity. It’s easy to verify that these functions satisfy equation (3) with λ = π. Therefore, to represent the function v(x) as a linear combination |
|
|
|
|
|
|
|
the coefficients given by our linear regression formula (2), with the summation changed to an integration, are |
|
|
|
|
|
and |
|
|
|
|
|
for j = 1, 2, … We recognize these as the coefficients of the well-known expressions for the Fourier series for v(x). Thus we’ve shown that these expressions emerge quite naturally from the formulas for simple linear regression, and it immediately generalizes to higher-dimensional functions with arbitrary basis functions and arbitrarily distributed samples with errors. |
|
|