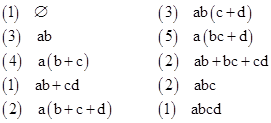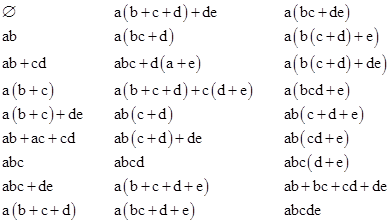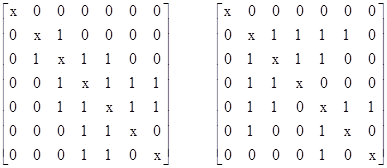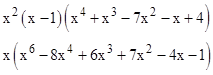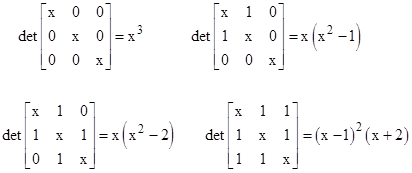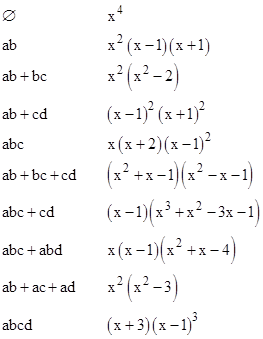|
Meeting Combinations and Interval Graphs |
|
|
|
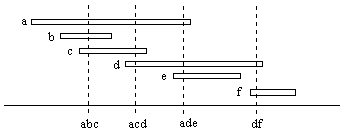
Let n continuous segments with freely defined starting and ending points be placed along the x axis, and consider the intersections between these segments. For any given arrangement there may be some regions where no segment is present, some where just one segment is present, some where exactly two segments overlap, some where exactly three segments overlap, and so on. Any such arrangement establishes a set of "meetings" between two or more segments. To illustrate, the figure below shows the placements of six segments, and identifies the meetings between them. |
|
|
|
|
|
|
|
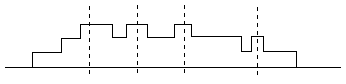
The meetings for this arrangement are abc, acd, ade, and df. In general, a meeting is a local maximum point on the plot of the number of segments present as a function of position. The plot for the above arrangement of six segments is shown in the figure below. |
|
|
|
|
|
|
|
The number of different arrangements of the starting and stopping points for n segments (with distinct identities) is easy to determine. For the first segment there is obviously only one arrangement. This segment divides the axis into three regions, namely, the region to the left of the starting point, the region between the starting and ending points (i.e., the region covered by the segment), and the region to the right of the ending point. Therefore, the starting point of a second segment can be placed in any one of those three regions, and the ending point can be placed in the same region or any other region to the right of the region containing the starting point. Thus there are six distinct ways of placing the second segment. |
|
|
|
In general, as we prepare to add the kth segment, there will already be k−1 segments in place, and the 2(k−1) terminal points of these segments divide the axis into 2k−1 regions. The starting point for the kth segment can be placed in any of these, and then the ending point is placed in the same or more rightward region. Thus the number of possibilities for placing both these points is (2k−1) + (2k−2) + ... + 2 + 1, which equals k(2k−1). It follows that if we let Nj denote the number of distinct arrangements of j segments, then we have |
|
|
|
|
|
|
|
This applies only if the n segments have specified identities. If we relax this condition, allowing the labels of the segments to be interchangeable, then the number of distinct arrangements is much less. In general we will have n starting points, so it only remains to place the n ending points. The only restriction is that each ending point must follow its starting point. Thus the ending point for the first segment (i.e., the segment with the left-most starting point) can be placed in any of n regions, delimited by the n starting points. The ending point of the second segment can be placed in any of the n−1 regions to the right of the second starting point. And so on. (The arrangement of the ending points in between consecutive starting points has no effect on the presence of intersections.) Consequently the number of arrangements for indistinguishable segments is simply (n!). |
|
|
|
However, this still distinguishes between the 1st segment, the 2nd segment, and so on. It is possible for two or more distinct arrangements to yield the same "meeting structure" up to permutation of the segments. For a trivial example, consider the two arrangements of three segments shown below. |
|
|
|
|
|
|
|
(The segment labels here merely indicate the order of the starting points, not implying any distinguishable identity for the segments.) In the arrangement shown on the left, the meeting structure is "ab", which signifies that the first and second segments overlap. In the arrangement on the right, the meeting structure is "bc", which signifies that the second and third segments overlap. If we don't care about the orderings of the start times for the segments in the meeting structure, then these two arrangements induce the same meeting structure. On this basis, what is the number of distinct meeting structures for n segments? |
|
|
|
Let M(n) denote the number of distinct meeting structures for n segments. Obviously for n = 0 and n = 1 segments, no meetings are possible, so there is only one meeting structure in each of these cases, namely the null structure, denoted by {Ø}. Thus we have M(0) = M(1) = 1. For n = 2 segments there are two possible meeting structures, corresponding to the fact that either these segments overlap or they do not. We will let {Ø, ab} denote these two possibilities, and we have M(2) = 2. |
|
|
|
For n = 3 segments, there are 3! = 6 distinct arrangements, which we can express symbolically as |
|
|
|
|
|
|
|
However, as noted above, the arrangements ab and bc represent the same meeting structure. Likewise the arrangement ab+bc is the same structure as ab+ac. In both cases, one segment meets with each of the other two, but the other two don't overlap with each other. Therefore, the number of distinct meeting structures for n = 3 segments is just four, consisting of the set {Ø, ab, ab+bc, abc}, and so we have M(3) = 4. |
|
|
|
At this point we should make it clear that although our notation for meeting structures looks like Boolean logical notation, it is not. For example, the meeting "abc" can also be written in the form "ab+ac+bc", because these both signify a triple intersection between the segments a, b, and c. In this notation, conjoined characters signify a mutual meeting of those segments, and the "+" symbol represents logical "AND". Thus both of these operations are forms of "intersection". It's important to note that if a,b,c represented arbitrary sets, then ab+ac+bc would not be equivalent to abc, because it would be possible to have those three pair-wise intersections with no three-way intersection. However, since our basic sets are continuous segments on the one-dimensional x axis, the three pairwise meetings of three segments imply that the first ending point occurs after the last starting point, so there is a region of three-way intersection. (It's interesting that the topology of continuous regions in one-dimensional space is induced by imposing the equality ab+ac+bc = abc, raising the question of whether other geometrical contexts can be specified in terms of some other Boolean equalities.) On the other hand, the "meeting" relation between segments is not transitive, because ab+bc does not imply ac. |
|
|
|
For n = 4 segments, we examine all n! = 24 distinct arrangements and find the following ten distinct meeting structures |
|
|
|
|
|
|
|
(The number to the left of each structure is the number of occurrences of that structure in the n! arrangements.) Hence we have M(4) = 10. |
|
|
|
To determine the value of M(5), we could examine each of the 5! = 120 arrangements by hand, and check for the unique structures, but this would be very laborious. To automate the process, we can step through each of the n! placements of the n ending points, and for each arrangement we can easily determine the pairwise meetings. We can then count how many pairs contain the first segment, how many the second, and so on. We can then count how many segments appear in exactly one pair, how many in exactly two, and so on. This gives a set of numbers d1, d2, ... that characterize the meeting structure, independent of the orderings of the segments. If two structures are characterized by different values of dj, then they are certainly distinct structures, so we can determine a lower bound on the value of M(n) by determining the number of unique characteristics {d1, d2, ... }. |
|
|
|
For the case n = 5, this criterion turns out to be nearly sufficient to distinguish all the structures. There are 26 distinct sets of {dj} indices, so we know M(5) is at least 26. However, it is possible for distinct meeting structures to have the same set of {dj} values. This occurs for the structures ab+ac+bc+de and ab+bc+cd+de. In each case, two letters appear exactly once, and the other three letters appear twice each. However, they are obviously different structures, as seen by the fact that the first one reduces to abc+de whereas the second is irreducible. So, there are actually M(5) = 27 distinct meeting structures with n = 5. These are shown below. |
|
|
|
|
|
|
|
To help distinguish structures that have the same {dj} sets, consider again the two structures ab+ac+bc+de and ab+bc+cd+de. If we replace each letter by the number of pairs in which it appears, these become 2×2 + 2×2 + 2×2 + 1×1 and 1×2 + 2×2 + 2×2 + 2×1 respectively, clearly distinct. Carrying out the multiplications and additions numerically, these give the values 13 and 12 respectively. These sums are an additional discriminator that can be used to help count the distinct meeting structures. On this basis, we can distinguish 91 meeting structures for n = 6. However, there are actually M(6) = 92 distinct meeting structures. The two that are indistinguishable based on the criteria we've described so far are ab + bc + de + df + ef and ab + bc + cd + de + ef. These have the same set of valences, and the same pairings of valences, but they are nevertheless distinct structures, as shown by the fact that the first can be reduced to ab + bc + def, whereas the second is irreducible. |
|
|
|
We can define another discriminator by replacing each letter not with the valence of that letter, but with the sum of the valences of all the letters with which it is paired. For example, in the first structure e is paired with d and with f, and these two letters appear twice each, for a total of 4, so we replace the letter e with 4. Doing the same for all the other letters in these structures, and carrying out the multiplications and additions numerically, we get |
|
|
|
|
|
|
|
So this criterion enables us to distinguish between these two structures. On the same basis we can determine that M(7) = 369, meaning that there are 369 distinct meeting structures for n = 7 segments. However, for n = 8 segments the criteria we have described so far are not sufficient to distinguish between all the different structures. We find that there are at least 1800 such structures by these criteria, but in fact there are 1807. It's interesting to try to identify the most efficient discriminators between these structures. Obviously if we are given two sets of pairing expressions we can simply try all possible permutations of the letters and terms, to see if they can be brought into agreement, but this in not feasible for large values of n. |
|
|
|
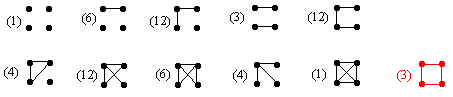
It's worth noting that if ajak is a connected pair with j < k, then ajai is also a connected pair for all indices i between j and k. For example, if bf is a connected pair, then bc, bd, and be are also connected pairs. It is this requirement that reduces the number of possible structures from 2n(n−1)/2 down to n!. We then need to allow for equivalence under all possible permutations of the letters to reduce the number of distinct structures from n! down to M(n). These structures are often called "interval graphs", because they can be represented pictorially as a set of connections between the n nodes of a plane graph. Consider, for example, all 24(4−1)/2 = 64 plane graphs involving four nodes, shown below. |
|
|
|
|
|
|
|
The numbers in parentheses indicate how many of each of these structures there are if we regard the nodes as having distinct identities. (A convenient check is given by confirming that the total numbers of graphs with k edges is C(6,k).) If, on the other hand, the nodes are regarded as indistinguishable (as is the convention for graphs), then the eleven arrangements illustrated above represent all the distinct graphs on four nodes. Ten of these graphs are interval graphs, corresponding to the ten "meeting structures" described previously. However, the "square cycle" graph shown on the right (in red) is not an interval graph, i.e., it does not correspond to any meeting structure of overlapping continuous intervals on a line. This stands to reason, because an interval graph cannot contain any minimal closed cycle of length greater than three. |
|
|
|
One way of characterizing the unique meeting structures for n segments is in terms of the determinant of a certain n´n matrix. Let ak with k = 1, 2,.., n designate the n segments, and define an n´n matrix A with the non-zero components Aj,k = 1 for each pair of indices j,k such that ajak (or akaj) is a connected pair. In addition, we set the diagonal values of A to the parameter x, so we have Aj,j = x for j = 1 to n. (Note that a meeting structure is specified as a union of m pair-wise connections. If no two segments meet, then m = 0. If there is a connection between every pair of segments, then m = n(n−1)/2.) |
|
|
|
Given the matrix A for a particular structure, the determinant of A is a polynomial in the parameter x. Since the determinant of a matrix is invariant under permutations of the row/columns, it follows that this polynomial characterizes a full equivalence class of meeting structures. Thus we can use these polynomials to discriminate between distinct structures. To illustrate, consider the following two meeting structures for n = 7 segments: |
|
|
|
|
|
|
|
These structures have the same valence sets (i.e., they each have two characters that appear in four pairs, one that appears in three pairs, two that appear in two pairs, and one that appears in one pair), so in order to distinguish between them using the previous method we need to go to higher-order valences. However, these structures correspond to the matrices |
|
|
|
|
|
|
|
and the determinants of these matrices are |
|
|
|
|
|
|
|
This shows how we can immediately distinguish between these two structures. (For automated numerical purposed, we can simply evaluate these polynomials for a few arbitrary values of x to discriminate between them.) |
|
|
|
The matrices and characteristic polynomials for the four distinct meeting structures for n = 3 segments are shown below. |
|
|
|
|
|
|
|
Likewise we can determine the characteristic polynomials for each of the 10 interval graphs on n = 4 nodes, shown below. |
|
|
|
|
|
|
|
As noted previously, the only other plane graph on four nodes is the four-loop |
|
|
|
|
|
|
|
which is not an interval graph. |
|
|