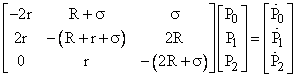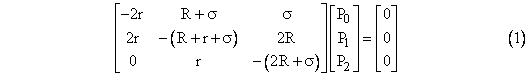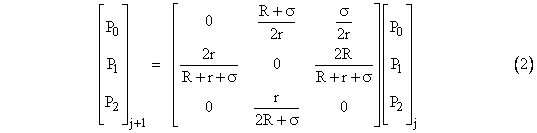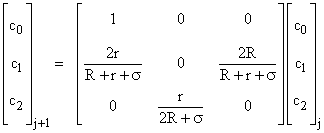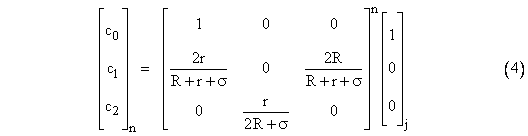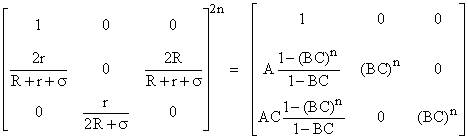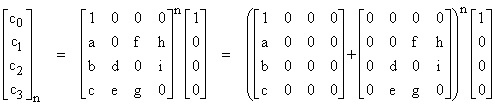|
Iterative Solutions of Homogeneous Linear Systems |
|
|
|
Suppose we are given a homogeneous linear system of equations such as |
|
|
|
|
|
|
|
with the auxiliary condition P0 + P1 + P2 = 1. (This system appears in the note on Redundant Systems with a Common Threat.) The steady-state solution satisfies the algebraic equations |
|
|
|
|
|
|
|
The coefficient matrix is singular (as can be seen from the fact that each column sums to zero), so there exists a solution other than the trivial solution P0 = P1 = P2 = 0 (which does not satisfy the auxiliary condition). A straight-forward approach to determining the non-trivial solution is to replace the first equation (say) with the auxiliary condition, giving the system |
|
|
|
|
|
|
|
Multiplying through by the inverse of the coefficient matrix gives the result |
|
|
|
|
|
|
|
For small systems this method works well, but for large systems the general matrix inversion becomes quite laborious, and for sparse systems (i.e., with many zeros in the coefficient matrix) it is inefficient. An alternative approach is suggested by re-writing equation (1) in the form of a recursion, moving the diagonal terms over to the right hand side and dividing through by the corresponding coefficients (assuming all the diagonal coefficients are non-zero, which is assured in many applications, such as Markov models). This gives |
|
|
|
|
|
|
|
where the subscripts signify the state vectors on successive iterations. (Of course, at steady-state, multiplication by this coefficient matrix would leave the system state unchanged.) Unfortunately, the iteration in (2) does not converge, so this is not a viable solution method. |
|
|
|
To understand why (2) doesn’t converge, a quick review of the most commonly used iterative methods for general non-homogeneous linear systems will be helpful. Given a system of the form Mx = b, where M is a square matrix and x and b are column vectors, suppose we divide each row equation by the corresponding diagonal coefficient of M (assuming all those diagonal elements are non-zero). Keeping the diagonal terms on the left side, and moving the off-diagonal terms over to the right side, we get an equivalent system of equations that can be written in the form x = Ax + u. for some square matrix A (will all diagonal terms equal to zero) and column vector u. Now suppose we employ this as a recurrence relation |
|
|
|
|
|
|
|
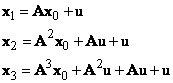
Beginning with an arbitrary initial state vector x0, successive iterations yield |
|
|
|
|
|
|
|
and so on. Thus the nth iterate can be written as |
|
|
|
|
|
|
|
Clearly if An goes to zero as n increases, then the first term vanishes and the geometric series in the second term converges, so we have |
|
|
|
|
|
|
|
which is obviously the solution of the original scaled system (I – A)x = u. This iteration scheme is known as the Jacobi method, which we see is essentially just a disguised way of inverting the coefficient matrix. It converges only if the powers of the depleted coefficient matrix A approach zero. This will be the case if the original coefficient matrix M is “strictly diagonally dominant”, meaning the magnitude of the diagonal term in each row exceeds the sum of the magnitudes of the off-diagonal terms in that row. To prove this, note that the sum of each row of A is strictly less than 1, because it consists of the off-diagonal terms of the corresponding row of M divided by the diagonal term of that row, whose magnitude (by assumption) exceeds the sum of the off-diagonal terms. Hence if we let c denote the column vector consisting of all 1's, it follows that Ac is a column vector consisting of terms all strictly smaller than 1, and so A(Ac) consists of even smaller terms, and so on. Thus Anc approaches zero, so An approaches zero. |
|
|
|
In some applications we encounter systems of equations for which the coefficient matrices are not diagonally dominant by rows, but they are diagonally dominant by columns. In other words, the sum of the magnitudes of the off-diagonal elements of each column is less than the magnitude of the diagonal term of that column. Such systems are still convergent under the Jacobi method. To see why, note that instead of dividing through each row by the diagonal coefficient of that row, we can re-scale each component of x so that the diagonal terms of the modified coefficient matrix become 1s. To accomplish this, we define a new variable column vector y by the relations yi = Miixi. Making these substitutions into the original system equations, we essentially just divide each element of a given column in the coefficient matrix by the diagonal element of that column. In this way we arrive at a relation of the form y = Ay + b where A is a square matrix with all zero diagonal elements, and such that the sum of the elements of each column is strictly less than 1. Just as in the previous case, iterations of this relation converge provided the powers of A approach zero. Letting r denote the row vector consisting of all 1s, the row vector rA consists of the sums of the columns of A, so the terms are all strictly smaller than 1, and hence the row vector (rA)A consists of even smaller terms, and so on. Thus rAn approaches zero, so An approaches zero as n increases. |
|
|
|
Given that the original coefficient matrix is strictly diagonally dominant either by rows or by columns, we can simply proceed as we did originally, solving each row for the diagonal term and setting up the recurrence. It isn’t necessary to normalize by columns, because the Jacobi method will converge regardless of whether we normalize by rows or by columns (assuming diagonal dominance in either of those two directions). This is because the two methods described above – one normalizing by rows and the other by columns – lead to normalized matrices with the same convergence properties. To prove this, let D be the diagonal matrix whose non-zero elements are the reciprocals of the diagonal elements of the matrix M. Now letting N denote the matrix M with the diagonal terms removed, we see that the matrix products DN and ND represent the coefficient matrices normalized by rows and by columns respectively. The powers of either of these products consist of alternating factors of D and N, so they both exhibit the same convergence. |
|
|
|
Here we should also mention that, although the Jacobi method consists of evaluating successive iterations of the entire state vector based on the previous state vector, we could also evaluate each row of the system using the updated component values as soon as they are calculated. This is known as the Gauss-Seidel method, and it typically converges about twice as fast as the Jacobi method. The condition for convergence is essentially the same, i.e., the coefficient matrix must be diagonally dominant. |
|
|
|
It should also be noted that strict diagonal dominance is a sufficient condition for convergence but not a necessary condition. Assuming a fully-connected system of equations, a weaker but still sufficient condition is that the magnitude of the diagonal term of each row (or each column) is at least equal to the sum of the magnitudes of the other elements of that row (or column), and for at least one row (or column) the magnitude of the diagonal element strictly exceeds the sum of the magnitudes of the other elements. This can be proven as with the previous propositions, but accounting for the fact that a reduction in the size of term in the c or r vector affects every column having a contribution from that row, and then every row having a contribution from any of those columns is affected, and so on. Assuming the system is fully-connected, it follows that all the elements of An go to zero an n increases. |
|
|
|
Returning now to our original example, the homogeneous equation (1), we can see why the Jacobi and Gauss-Seidel methods do not converge. The system of equations is diagonally dominant by columns, but not strictly diagonally dominant is any column. This is true in general for the steady-state equations of Markov models in reliability calculations. Successive powers of the coefficient matrix in (2) remain bounded, but they oscillate endlessly, as we would expect for a matrix with spectral radius of 1. As a result, the Jacobi or Gauss-Seidel methods would not be very suitable for solving this system, even if it had a non-zero “forcing state” (i.e., even if it had a non-zero u vector in equation (3)). Similar comments apply to more complicated systems, such as the one described at the end of the note on Undetected Failures of Threat Protection. |
|
|
|
However, it is possible to solve such systems very efficiently by an iterative method, taking advantage of the homogeneity of the equations. We might impose the auxiliary condition to replace one of the rows, but it is preferable to leave that condition aside for the moment, and notice that the absolute values of the Pj variables are irrelevant, since only their ratios have significance (with respect to this system of equations). We can exploit this fact by dividing through all the equations by P0, resulting in a new set of equations in the ratios cj = Pj/P0. Now, a consequence of this normalization is that c0 is identically equal to 1, so we can re-write equation (2) in terms of the cj variables and replace the first row with the identity, giving the equations |
|
|
|
|
|
|
|
The auxiliary condition implies c0 + c1 + c2 = 1/P0, so we have Pj = cj /(c0+c1+c2). For convenience we can stipulate that the initial c vector was [1 0 0]T, allowing us to write |
|
|
|
|
|
|
|
This amount to using each of the original equations as recurrence relations to compute successive c vectors, analogous to the Jacobi method. (Of course, we could also proceed row-by-row, making use of each coefficient as soon as it is available, analogous to the Gauss-Seidel method, and the results would be similar, but with faster convergence.) Since the system has a unique non-trivial steady-state solution, we expect the powers of the coefficient matrix to converge on a fixed matrix. Indeed, for this simple system, we have |
|
|
|
|
|
|
|
where |
|
|
|
|
|
|
|
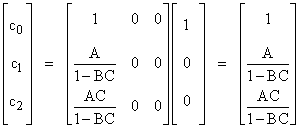
The odd powers behave similarly. Notice that the product BC involves the numerators and denominators from the 2nd and 3rd rows/columns, illustrating why it doesn’t matter whether we normalized by rows or by columns. If the original matrix is strictly diagonally dominant either by rows or by columns, the product BC is less than 1, and therefore the iteration converges to |
|
|
|
|
|
|
|
It is easily verified that this result is equivalent to the explicit solution given previously. |
|
|
|
In general, for homogeneous linear systems representing steady-state Markov models, the original coefficient matrix is diagonally dominant by columns, although not strictly in any column. However, there are invariably transitions back to the initial state for any closed-loop model, and these are represented by positive components in the first row of the matrix. Once this row is set to zero (except for the leading entry of 1), the resulting columns are then strictly diagonally dominant. After solving for the diagonal terms of the original homogeneous system, and dividing through by the first variable (P0) we get a system of the form |
|
|
|
|
|
|
|
Let C denote a square matrix with 1 in the upper left corner and whose only other non-zero elements are in the first column, and let H denote a square matrix with all zero elements in the first row and column and diagonal, and let Q denote a square matrix with 0 in the upper left corner and whose only other non-zero elements are in the first column. Then we have the identities |
|
|
|
|
|
|
|
and of course the sum of a C matrix and a Q matrix is a C matrix. In terms of these types of matrices, the preceding equation can be written as |
|
|
|
|
|
|
|
Of the 2n terms given by raising C + H to the nth power, the only terms not containing CH (and hence the only non-zero terms) are |
|
|
|
|
|
|
|
Since the sub-matrix of H is strictly diagonally dominant (by columns), we know that Hn goes to zero as n increases, and the geometric series converges, so we have |
|
|
|
|
|
|
|
Typically the first column converges very rapidly – within just five or ten iterations – even before the powers of H have become negligible. For some applications of this method, see the note on Complete Markov Models and Reliability. |
|
|
|
Needless to say, this method has much in common with numerical techniques for solving potential flow fields in computational fluid dynamics. We are given a grid with specified values of the flow function at the boundaries, and then the value of each “node” is computed as a function of the values of the neighboring nodes such that the Laplace equation (in discrete form) is locally satisfied. We step through the grid, imposing the governing equation at each point, and then iterate. Eventually the entire flow field is determined so that the homogeneous Laplace equation is simultaneously satisfied at each point. Likewise in our iterative approach to solving homogeneous linear systems we have a set of “nodes” with governing equations giving the value of each node in terms of the values of the “neighboring” nodes. However, in this case there is no notion of “locality”, because any node can be a function of any other node. In sparse models the number of dependent nodes is quite limited, but they need not be in close “proximity” in terms of any low-dimensional space. |
|
|