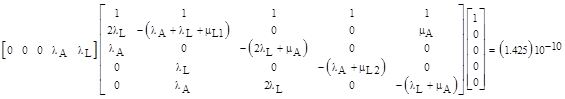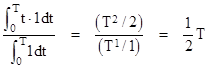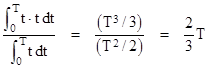|
Fault Trees and Markov Models |
|
|
|
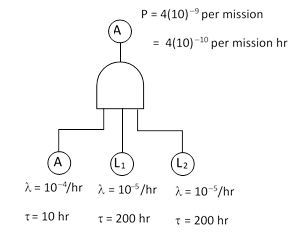
Consider a system consisting of one continuously monitored active component, with failure rate λA = 10–4 per hour, and two un-monitored back-up components with failure rates λL = 10–5 per hour, and suppose the individual mission length is 10 hours (during which no repairs are possible). The un-monitored components are checked and repaired every 200 hours, i.e., every 20 missions. |
|
|
|
The two most common techniques used for evaluating the reliability of such a system are fault trees and Markov models. The traditional way of assessing the failure probability of this system using a fault tree is as shown below. |
|
|
|
|
|
|
|
This represents the probability of total system failure during the “last” 10-hour mission in each 200-hour inspection interval, because the probability of each latent fault is taken to be the value it has at the end of the 200 hours. Also, note that the probability criteria imposed by safety regulations is ordinarily interpreted to be the probability of catastrophic failure per mission, normalized to a per hour basis. Thus we compute the probability of catastrophic failure during the last 10-hour mission, and then divide this by 10 to give the normalized probability for determining compliance to the numerical criteria of the requirements. |
|
|
|
This approach obviously has some conservatism built into it, because it represents the worst dispatchable mission, rather than the average mission risk. The risk on the average mission is about 1/3 of this, because it is virtually zero during the initial missions (when the chances of either of the latent faults – let alone both – is virtually nil), but then increases quadratically during the 200 hour inspection interval. (The factor of 1/3 comes from the fact that the probability increases in proportion to the time squared, and the mean value of t2 for t = 0 to T is 1/3 of the value at t = T.) Therefore the average normalized risk is roughly (1.333)10–10. |
|
|
|
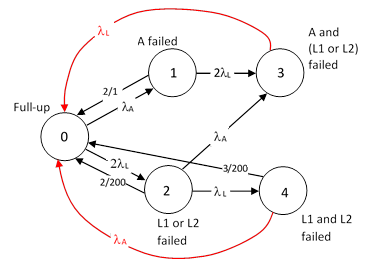
The average risk for this system can also be computed using a Markov model, with the failure and repair transitions shown in the figure below. |
|
|
|
|
|
|
|
In terms of the repair rate parameters μL1 = 2/200, μL2 = 3/200, and μA = 2/10, the solution of this model is given by |
|
|
|
|
|
|
|
Notice that we’ve used 2/200 for μL1 because the rate of entry into the single latent fault state is essentially constant over the inspection interval of T = 200 hours, so the mean time of entry is |
|
|
|
|
|
|
|
Hence the mean time from entry to inspection is T – (T/2) = T/2, so we use the inverse of this to approximate the repair rate. On the other hand, the rate of entry into the dual latent fault state increases linearly over each inspect interval, so the mean entry time is |
|
|
|
|
|
|
|
Hence the mean time from entry to inspection is T – (2T/3) = T/3. This is why we use 3/200 to approximate the repair rate from the dual-latent-fault state. |
|
|
|
The value of the average mission failure probability (normalized to a per-hour basis) given by the Markov model is (1.425)10–10, which is fairly close to the rough estimate of (1.333)10–10 given by the fault tree analysis discussed previously. The difference between these two values is small in comparison with the uncertainties in the basic failure rates, as well as the ambiguities in the repair rates. (We modeled periodic repairs as if they were constant-rate transitions, even though this is not strictly correct.) Therefore, either the fault tree or the Markov model can be used to give reasonable estimates of the average failure rate. |
|
|
|
The
numerical agreement between the two methods could be made more precise (if
this was deemed necessary) by refining the evaluation of the average mission
reliability in the fault tree. Specifically, we need to use appropriate
values for the fault tree input probabilities for the N = 20 missions in each
200 hour interval, where each mission is T = 10 hours. The probability of the
active component failing during a mission is TλA for each
mission, whereas the probabilities for the latent components are nTλL
for the nth mission. So, for the probability of total failure on the nth
mission, our fault tree analysis gives |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Of course, to some extent the terms “fault tree” and “Markov model” are inappropriate here, because in neither case are we using a pure version of those methods. In both cases we performed computations outside of the basic calculation, such as to compute the repair transition rate for the dual-latent-fault state in the Markov model. The answer given by the model depends crucially on that rate, but the rate is being computed externally and input to the model. Even for the single-fault states, the period repairs are not strictly Markovian, so we must convert the specified periods to approximate rates. These calculations are not part of the Markov model. Likewise our evaluation of the average value of N fault trees with varying failure probabilities is not strictly part of a fault tree calculation. We are carrying out a sort of hybrid method, and the difference between the methods is, to some extent, one of semantics. Each combination of fault tree input conditions corresponds to a state of the Markov model, so we can directly map our calculations from one method to the other. Ultimately the differences are only in terminology and representation. |
|
|