|
Expulsion Sets |
|
|
|
These miracles we did; but now, alas, |
|
All measure and all language I should pass, |
|
Should I tell what a miracle she was. |
|
John Donne |
|
|
|
Let U denote a set closed under the commutative operation "+", meaning that if u1,u2 (not necessarily distinct) are in U, then u1 + u2 is also in U. We define an expulsion set in U under the operation "+" as any subset A of U such that if a1,a2 are in A then a1 + a2 is not in A. For example, among the integers the set {3,5} is an expulsion set under addition, because none of the integers 6=3+3, 8=3+5, 10=5+5 is in the set. |
|
|
|
Among the integers, a more natural example of an expulsion-set is the set of odd integers under addition. Among the reals, the set of negative numbers under multiplication constitutes an expulsion set. Both of these examples are maximal, because no additional elements of the background set can be adjoined while preserving the expulsion property. |
|
|
|
Another example among the integers is the set of primes under multiplication. However, this is not maximal, because we could adjoin various composites (e.g., all products of an odd number of primes) without destroying the expulsion property of the set. |
|
|
|
Given an expulsion set F of U with the operation "+", let T denote U−F, i.e., T is the complement of F in U. If this partition of the elements of U is such that the application of "+" to elements of the two subsets is as shown below |
|
|
|
F T |
|
--- --- |
|
F T F |
|
T F T |
|
|
|
then F is a special kind of an expulsion set, called a negation set. Clearly the odd integers under addition constitute a negation set, as do the negative reals under multiplication. On the other hand, the prime integers are not a negation set, because the product of a composite and a prime is not a prime. |
|
|
|
Based on these examples it might seem that an expulsion set is a negation if and only if it is maximal, but that is not the case, because while every negation is maximal, not every maximal expulsion set is a negation. For example, consider the integers congruent to +1 or -1 modulo 5 under addition. It's clear that the sum of any two such elements is congruent to -2, 0, or +2 (mod 5), so it is an expulsion set, and adjoining any number congruent to -2,0,or 2 will destroy the expulsion property, so it is maximal. However, it is not a negation set, because of sums such as 1 + 2 = -2 (mod 5). |
|
|
|
If we focus on just the maximal expulsion sets among the natural numbers under addition, we've seen that the odd numbers constitute an expulsion set, and they comprise (asymptotically) half of all the naturals. On the other hand, the integers congruent to ±1 (mod 5) comprise just 2/5 of the naturals. This raises the question: what is the most sparse maximal expulsion set among the natural numbers? |
|
|
|
If we begin with 1 and apply the greedy algorithm to generate a maximal expulsion set, i.e., if we adjoin the smallest number not already excluded at each step, then we simply arrive at the odds. To generate a sparse maximal expulsion set we need to apply an algorithm that is the opposite of greedy. At each stage, we determine the smallest number not yet excluded, but instead of adjoining that number to our set, we adjoin the sum of that number and the highest number already in the set. This excludes the number without having to adjoin it to the set. Formally, we can generate this sequence of numbers by setting a0 = 0 and then letting an+1 = an + d where d is the least natural number not equal to aj + ak, aj – ak, or aj/2 for any j,k ≤ n. |
|
|
|
Beginning with 1, we can apply this algorithm to give the following maximal expulsion set of natural numbers |
|
|
|
1 4 10 17 29 44 67 91 117 148 |
|
180 215 251 288 329 371 420 471 523 576 |
|
631 687 746 806 870 935 1004 1074 1146 1221 |
|
1297 1376 1456 1538 1623 1709 1802 1896 1993 2092 |
|
2194 2300 2409 2519 2631 2753 2876 3001 3127 3255 |
|
3385 3518 3655 3796 3939 4084 4234 4387 4541 4698 |
|
4864 5032 5204 5377 5551 5729 5914 6102 6295 6490 |
|
6689 6889 7091 7294 7500 7713 7931 8157 8384 8612 |
|
8841 9072 9305 9541 9778 10020 10263 10509 10758 11015 |
|
11281 11550 11824 12101 12380 12661 12960 13261 13570 13883 ... |
|
|
|
The first differences of these numbers are as shown below: |
|
|
|
1 3 6 7 12 15 23 24 26 31 |
|
32 35 36 37 41 42 49 51 52 53 |
|
55 56 59 60 64 65 69 70 72 75 |
|
76 79 80 82 85 86 93 94 97 99 |
|
102 106 109 110 112 122 123 125 126 128 |
|
130 133 137 141 143 145 150 153 154 157 |
|
166 168 172 173 174 178 185 188 193 195 |
|
199 200 202 203 206 213 218 226 227 228 |
|
229 231 233 236 237 242 243 246 249 257 |
|
266 269 274 277 279 281 299 301 309 313 |
|
|
|
Notice that these differences increase at a roughly constant rate, as confirmed by the second differences shown below: |
|
|
|
1 2 3 1 5 3 8 1 2 5 |
|
1 3 1 1 4 1 7 2 1 1 |
|
2 1 3 1 4 1 4 1 2 3 |
|
1 3 1 2 3 1 7 1 3 2 |
|
3 4 3 1 2 10 1 2 1 2 |
|
2 3 4 4 2 2 5 3 1 3 |
|
9 2 4 1 1 4 7 3 5 2 |
|
4 1 2 1 3 7 5 8 1 1 |
|
1 2 2 3 1 5 1 3 3 8 |
|
9 3 5 3 2 2 18 2 8 4 |
|
|
|
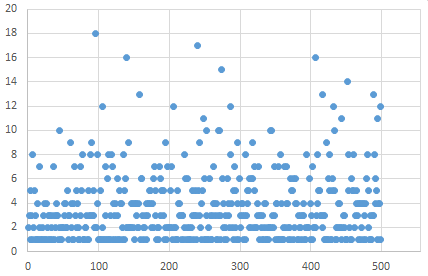
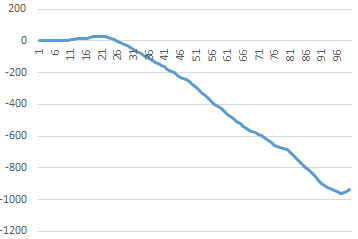
Several interesting questions about this expulsion set arise. For example, what is the asymptotic behavior of the set? It appears that the sum of the inverses converges to a value slightly above 1.5727... What exactly is this value? Are there infinitely many second differences equal to 1? Why is there no second difference of 6 until the 114th term? The largest second difference for the first 500 terms of the sequence is 18, which occurs at the 97th term. Is there an upper limit on the size of the second differences? There doesn’t appear to be any secular trend in the second differences, as shown in the plot below. |
|
|
|
|
|
|
|
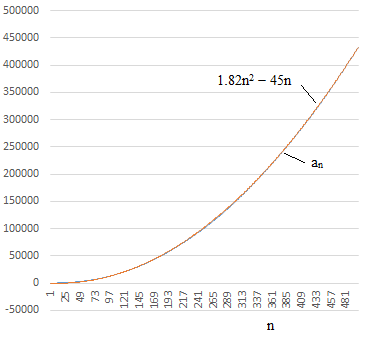
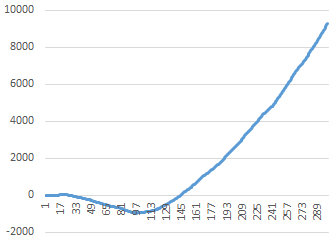
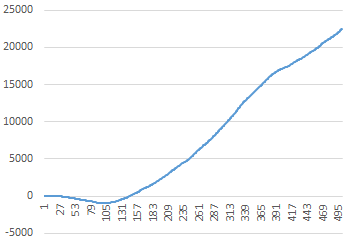
Since these “second derivatives” are stationary, we would expect the quantities an to be asymptotic to a function of the form an ≈ An2 + Bn, and indeed up to the 500th term we find an excellent match with A = 1.82 and B = −45, as shown by superimposing this function on the actual values of an in the figure below. |
|
|
|
|
|
|
|
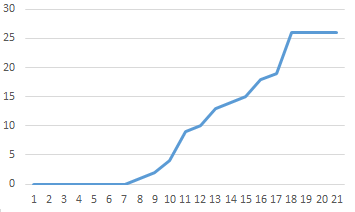
Incidentally, in generating this sparse expulsion set it would be easy to overlook the fact that the incremental difference d must exclude not only all numbers of the form aj+ak and aj−ak but also numbers of the form aj/2. If we omit that last condition, we generate the same initial sequence of values 0, 1, 4, 10, 17, 29, 44. We get these same initial values because 4/2 was already excluded by 1+1, and 10/2 was already excluded by 1+4, so the condition on aj/2 was redundant. However, the number 44/2 is not excluded by any sum or difference of smaller terms, so it is necessary to explicitly exclude all numbers of the form aj/2. If we omit this condition, the next number in the sequence after 44 would be 44+22 = 66, whereas the correct next term (consistent with the definition of d as the smallest natural number not already excluded) is 44+23 = 67. One might assume that the terms of the correct sequence would always grow more rapidly than those of the alternate sequence (i.e., omitting the condition on aj/2). Indeed this is initially the case, as shown by the plot below of the difference between these two sequences up to the 20th terms. |
|
|
|
|
|
|
|
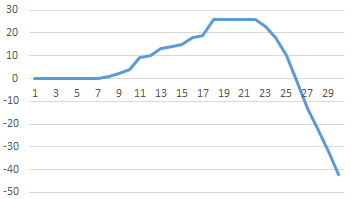
However, if we plot the differences up to the 100th terms we find the somewhat surprising result shown in the plot below. |
|
|
|
|
|
|
|
This shows that the terms of the sequence formed without imposing the aj/2 condition actually grows faster in this range than the terms of the sequence with that condition. Even more surprising, this persists even up to the 100th terms of the sequences, as shown by the differences in the plot below. |
|
|
|
|
|
|
|
However, by the 300th terms of the sequences, the lead has changed hands again, and the terms of the sequence formed with the condition aj/2 exceed the terms of the other sequence, as shown by the plot of the differences below. |
|
|
|
|
|
|
|
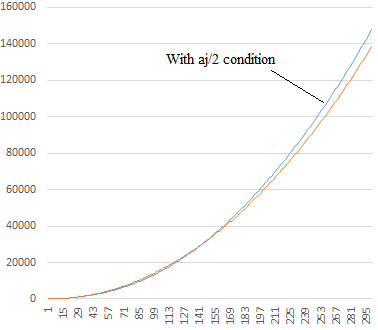
The absolute values of the two sequences up to the 300th terms are shown in the figure below. |
|
|
|
|
|
|
|
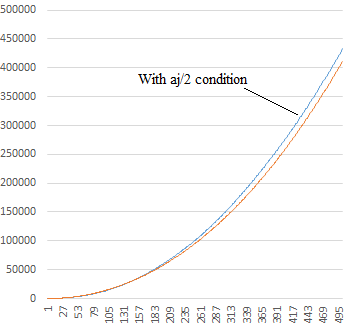
This trend continues, as shown in the plot below for the absolute values of the sequences up to the 500th terms. |
|
|
|
|
|
|
|
However, the rate of increase of the difference between the sequences undergoes an appreciable reduction at the high end of this range, as shown by the plot of differences below. |
|
|
|
|
|
|
|
The growth rates of sequences like these seem to have self-correcting oscillations that can sustain “waves”, because the faster the terms grow at any stage (taking large steps), the slower they grow at a later stage (due to the large gaps left by the large steps), and vice versa. It would be interesting to know the precise asymptotic expressions for the terms of these sequences. |
|
|
|
For another application of expulsion sets, recall that Fermat observed no sum of two cubes is a cube, so the set of cubes {1,8,27,...} is an "expulsion set" under addition, but of course the cubes do not constitute a "maximal" expulsion set (over the integers), because it's possible to adjoin other integers to them with the result still being an expulsion set. Now, we can't adjoin 2, because 1+1=2, but we can adjoin the integer 3 to the cubes to give a larger expulsion set. This too is not maximal. We cannot adjoin 4=3+1, nor can we adjoin 5=8−3, nor 6=3+3, nor 7=8-1, nor 9=8+1, but we can adjoin 10. Continuing on is this "greedy" way, adjoining the next smallest allowable number at each step, we arrive at a maximal expulsion set containing the cubes as a subset: |
|
|
|
[1] 3 [8] 10 12 14 21 23 25 [27] 34 36 38 40 45 |
|
47 49 51 58 60 62 [64] 69 71 73 75 82 84 86... |
|
|
|
and so on. This sequence contains 176 numbers less than or equal to 1000. |
|
|
|
Clearly this is not the only maximal expulsion set containing the cubes; it is just the one that is produced by strictly applying the greedy algorithm. If we had chosen to adjoin 5 instead of 3 on the first step, and then applied the greedy algorithm thereafter, we would have produced the maximal expulsion set {1,5,8,11,14,17,20,23,27,29,33,36,...}. Depending on our free choices, the density of the resulting sequence can vary. For example, the pure greedy algorithm gave a maximal set with 176 of the first 1000 integers, whereas if we had initially adjoined "6" to the cubes, the greedy algorithm then produces a maximal set that contains only 136 of the first 1000 integers. Even better, if we initially adjoin the integers 6, 23, and 34 to the cubes, the greedy algorithm then gives a maximal expulsion set consisting of just 108 of the first 1000 integers. |
|
|
|
What is the most sparse maximal expulsion set containing the cubes? If we initially adjoin the numbers 6, 23, 39, 112, 137, 140, and 219, we get a set that consists of just 96 of the first 1000 integers, which is just over half the size of the set given by the pure greedy algorithm. Can anyone find a set that contains fewer numbers in this range? Is there an algorithm (other than trial and error) for selecting the integers to be adjoined to the cubes in such a way as to produce the most sparse maximal expulsion set up to arbitrarily large numbers? |
|
|
|
We can also consider expulsion-sets in the context of groups. If G is any commutative group, and H is a subgroup of G, then obviously the set G−H does not contain the identity element, and so it can be partitioned into disjoint expulsion-groups, usually in multiple ways. The trivial way is just to consider each individual elements of G−H as an expulsion-group. Of course, none of these individual elements is a maximal expulsion-group. However, it appears that G−H can always be partitioned into disjoint maximal expulsion-groups. This is obviously true for the group of permutations of three objects, and more generally for any group of prime order. Is there a simple proof for arbitrary commutative groups? |
|
|