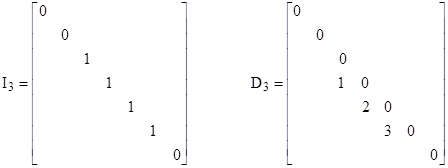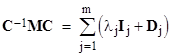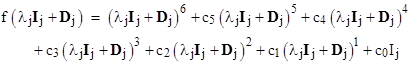|
The Cayley-Hamilton Theorem |
|
|
|
Every square matrix satisfies its own characteristic equation. This interesting and important proposition was first explicitly stated by Arthur Cayley in 1858, although in lieu of a general proof he merely said that he had verified it for 3x3 matrices, and on that basis he was confident that it was true in general. Five years earlier, William Rowan Hamilton had shown (in his “Lectures on Quaternions”) that a rotation transformation in three-dimensional space satisfies its own characteristic equation. Evidently neither Cayley nor Hamilton ever published a proof of the general theorem. References to this proposition in the literature are about evenly divided in calling it the Cayley-Hamilton theorem or the Hamilton-Cayley theory. The first general proof was published in 1878 by Georg Frobenius, and numerous others have appeared since then. |
|
|
|
Depending on how much of elementary linear algebra and
differential equations we take for granted, the proof of the Cayley-Hamilton
theorem can be fairly immediate. For an arbitrary square matrix M with
characteristic equation f(z) = 0, the general solution of the linear system |
|
|
|
However, this proof could be criticized for taking too much for granted. It makes use of the exponential form of the general linear system solution, and of the fact that x satisfies the differential operator form of the characteristic equation. These are familiar and not very difficult propositions, but it might be argued that they are no more self-evident than the fact we are trying to prove. |
|
|
|
As an alternative, consider again the homogeneous linear
first-order system |
|
|
|
|
|
|
|
where the aj exponents are zero for the first
appearance of a given eigenvalue and incremented for each subsequent
appearance. The derivative of x is |
|
|
|
If there are repeated eigenvalues, then C–1MC is the sum of the diagonal matrix of the system’s eigenvalues plus a “differentiation matrix”. For each distinct eigenvalue λj with multiplicity mj, let Ij denote the diagonal matrix with unit elements in each location where λj occurs, and let Dj denote the differentiation matrix comprised of integers counting the repeated eigenvalues, placed to the left of the diagonal locations of the respective eigenvalues. For example, if a seventh-order system has eigenvalues λ1, λ2, λ3, λ3, λ3, λ3, λ4, then the I3 and D3 matrices are |
|
|
|
|
|
|
|
In terms of these matrices, we have |
|
|
|
|
|
|
|
where m is the number of distinct eigenvalues. The matrices for the distinct eigenvalues are independent, so it suffices to show that f(λjIj + Dj) = 0 for arbitrary j in order to prove that f(C–1MC) = 0. To show this, we can substitute directly into the polynomial as follows: |
|
|
|
|
|
|
|
Letting k denote the number of copies of the eigenvalue in this component, we can expand the powers and re-arrange terms to give the expression |
|
|
|
|
|
|
|
The matrix Djk is identically zero, and each of the other terms also vanish because λj is a root of the first k–1 derivatives of f. Therefore, we’ve shown that f(C–1MC) = 0, even when there are duplicated eigenvalues. By the same argument as before, it then follows that f(M) = 0, completing the proof. |
|
|
|
Incidentally, these two proofs of the Cayley-Hamilton
theorem mirror the Heisenberg and Schrödinger versions of quantum mechanics.
Both proofs begin with the linear system |
|
|