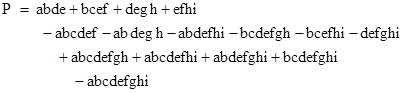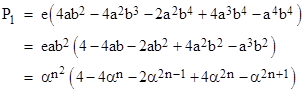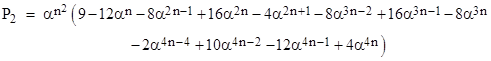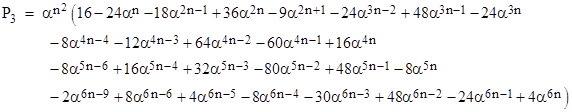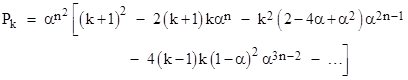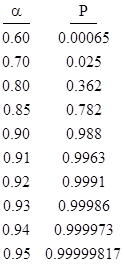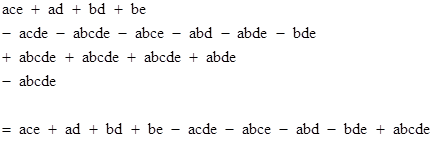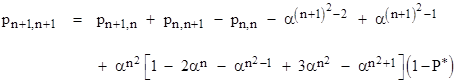|
Two-Dimensional Runs in Bernoulli Trials |
|
|
|
Suppose we have a tray with a 20x20 grid of "dimples" onto which marbles can be placed. We dip this tray into a large barrel of red and blue marbles, with a population density of α = 0.95 red and β = 0.05 blue marbles, and each dimple acquires a marble. What is the probability of achieving at least one 5x5 square region of all red marbles? |
|
|
|
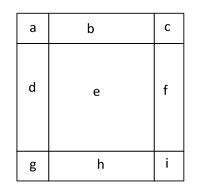
In principle, given an m-by-m square grid, we can determine the probability of at least one n-by-n regions of “successes” (i.e., red marbles) by direct application of inclusion-exclusion. For example, if m = n+1 there would be only four possible n-by-n regions, and we could represent these by unions of the nine mutually exclusive regions shown in the figure below. |
|
|
|
|
|
|
|
Letting the letters denote the event that the respective regions consists of nothing but successes (i.e., red marbles), the event of having one or more n-by-n regions of successes has the Boolean representation |
|
|
|
|
|
|
|
If we now let the letters signify the probabilities of the respective events, we can apply inclusion-exclusion to give |
|
|
|
|
|
|
|
The probabilities of the individual events are |
|
|
|
|
|
|
|
so the probability P1 of one or more n-by-n runs in a region of size (n+1) by (n+1) is |
|
|
|
|
|
In the same way we can determine that the probability P2 of one or more n-by-n runs in a region of size (n+2) by (n+2) is |
|
|
|
|
|
|
|
Likewise the probability P3 of one or more n-by-n runs in a region of size (n+3) by (n+3) is |
|
|
|
|
|
|
|
These results suggest that the first several terms of Pk are given by |
|
|
|
|
|
|
|
so if α is sufficiently small (say around 0.5 or lower) these terms could be used to approximate the answer. For example, if our original problem had specified a probability of 0.6 for the red marbles (instead of 0.95), we could accurately compute the result 0.00062 using these few terms. Unfortunately for values of α approaching 1, the result doesn't converge unless nearly all of the terms are included. Since the number of terms seems to at least double with each increment of k, it seems there would be well over 100,000 terms in the full expression for P15. |
|
|
|
Of course, one very simple way of placing a lower limit on the answer for large values of α is to consider mutually exclusive regions. We know that the probability of any particular 5x5 region containing nothing but red marbles is (0.95)25 = 0.2773..., and this applies to each of the 16 mutually exclusive 5x5 regions. The probability of any k of these events is simply the kth power of the probability of one of them, so the probability of the union is |
|
|
|
|
|
|
|
This represents a lower bound on the probability that any of these mutually exclusive 5x5 regions is all red. |
|
|
|
To improve this lower bound, recall that in the one-dimensional case we can express the probability of a run of n consecutive successes (each with probability ε) in a sequence of m Bernoulli trials by a simple recurrence relation. Letting pj denote the probability that the sequence of trials from 1 to j contains at least one run of n consecutive successes, we have p1 = p2 = pn−1 = 0, and pn = εn. For each subsequent trial the probability pj of having at least one run to that point equals the previous probability pj−1 plus the probability that [the preceding j−1 trials did not contain a run but the entire sequence up to the jth trial does contain a run]. The event in square brackets is true if and only if the last n trials (i.e., the trials j, j−1, j−2, …, j−n+1) were all successes and the trial j−n was a failure and the sequence of trials up to j−n−1 did not contain a run. Thus the probability pj can be expressed as |
|
|
|
|
|
|
|
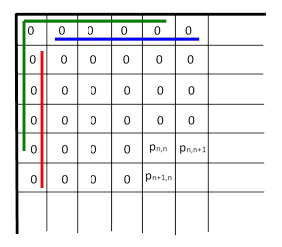
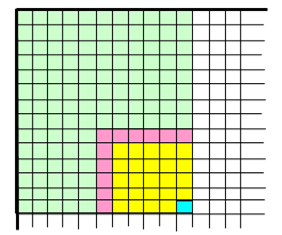
This formula enables us to recursively compute the probability of one or more runs in a sequence of any given length. The ranges of the sequence involved in this formula are illustrated in the figure below for the case n = 5. |
|
|
|
|
|
|
|
The recurrence formula asserts that the probability for the entire range up to the blue cell to contain a run equals the probability for the range up to the adjacent yellow cell, plus the probability that the blue and yellow cells are all successes and the pink cell is a failure and the entire green range does not contain a run. |
|
|
|
Using this result we can improve the lower bound on the two-dimensional problem by partitioning the original 20x20 grid into four mutually exclusive 20x5 stripes. If Q denotes the probability Q that a stripe contains one or more 5x5 square of pure red, then a lower bound on the overall probability is given by 1 − (1 − Q)4. To determine Q we can treat a stripe as a one-dimensional sequence of Bernoulli trials. Each 5x1 row of a stripe has a probability of ε = (0.95)5 = 0.7737... of being all red, and so Q is the probability of getting one or more "runs" of length 5 in a sequence of 20 trials. Letting pj denote the probability of one or more runs of 5 in j trials, we have the recursive relation |
|
|
|
|
|
|
|
with the initial values |
|
|
|
|
|
|
|
From this we can compute Q = p20 = 0.880786..., and therefore we have the lower bound for the entire 20x20 square of |
|
|
|
|
|
|
|
To verify that these lower bounds are valid, we can estimate the result numerically by means of a Monte Carlo simulation. Simulating a 20x20 array of dimples, each with probability α of being red, we find that the approximate probabilities of at least one 5x5 region of pure red marbles for various values of α are as tabulated below. |
|
|
|
|
|
|
|
These numerical results show that, if each dimple has probability of 0.95 of being filled by a red marble, then the probability of at least one 5x5 region of all red marbles differs from 1 by only about 1.8E-6. Also, the probability rises rapidly from near zero to near unity as α increases from about 0.70 to about 0.90. |
|
|
|
One possible approach to computing the exact answer explicitly is to determine a two-dimensional recurrence relation analogous to the recurrence for one-dimensional runs. In general, given an m-by-m square array of Bernoulli trials with probability α of success on each individual trial, we seek the probability that the array will contain at least one n-by-n square of successes. Letting pi,j denote the probability that a rectangle of i columns and j rows contains at least one such n-by-n two-dimensional run, we obviously have pi,j = 0 for all i,j such that i < n or j < n, and we have |
|
|
|
|
|
|
|
Incidentally,
in the special case n = 1 we have |
|
|
|
|
|
|
|
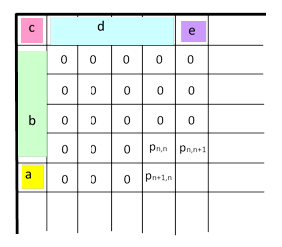
At this point we have the values depicted in the figure below for the case n = 5. |
|
|
|
|
|
|
|
We next need to determine the value of pn+1,n+1. By reasoning analogous to the one-dimensional case, we can say that this equals the probability of one or more runs in the square region extending to the cell [n+1,n+1] but excluding that cell, plus the probability that a run is completed by that cell but there were no other runs in that square region. It might seem as if the first quantity would be given by pn+1,n + pn,n+1 – pn,n, which would give |
|
|
|
|
|
|
|
However, this doesn’t fully account for all the inter-dependencies of overlapping runs. To determine the correct expression, note that there are only three possible positions for an n-by-n run in the region excluding the cell [n+1,n+1], and the probability of the union is given by inclusion-exclusion as |
|
|
|
|
|
|
|
To this we must add the probability that a run is completed by the cell [n+1,n+1] and there are no other runs in the overall region. This condition entails that all n2 cells leading up to the subject corner are successes, and there is at least one failure in each of the three overlapping regions marked with blue, green, and red bars in the figure below. |
|
|
|
|
|
|
|
We can partition those cells into five groups, designated a through e as shown below. |
|
|
|
|
|
|
|
The Boolean expression for the required failures is |
|
|
|
|
|
|
|
Letting the letters denote the probabilities of the individual components, the probability of the overall event is given by inclusion-exclusion as |
|
|
|
|
|
|
|
In each region we require that at least one cell is a failure, i.e., not all the cells are successes, so the individual component probabilities are |
|
|
|
|
|
|
|
Inserting these values into the preceding expression, we get |
|
|
|
|
|
|
|
So, multiplying this by α to the power n2 and adding the result to expression (1), we arrive at the probability |
|
|
|
|
|
|
|
Naturally this is identical to the expression for P1 derived previously. The analogy with the one-dimensional recurrence is clarified if we write this as follows |
|
|
|
|
|
|
|
where P* is the probability of one or more 5x5 red regions in overall square region less the 5x5 square at the outer corner. For this particular case, P* = 0, but in general it is not zero. To calculate the probabilities of all the cells in the entire 20x20 grid, we need to generalize this formula to accommodate the general case illustrated below. |
|
|
|
|
|
|
|
Given the probabilities for the rectangular regions extending from the outer boundary to each of the green, pink, and yellow cells, we wish to compute the probability for the blue cell. Just as in the one-dimensional case, this will equal the probability for the region extending from the boundary up to the adjacent yellow cells, plus the probability that the blue and yellow cells are all successes and the pink cells are not contained in any runs and there are no runs in the green cells. The task therefore reduces to determining a general expression for the probability that the union of two overlapping rectangular regions contains a run, given the probabilities of containing a run for each of the rectangular regions within that union. |
|
|
|
Another approach would be to regard the m2 trials as a linear sequence (reading left to right and top to bottom), and treat the squares of successes as linear patterns, e.g., with m=5,n=2 the squares are just linear sequences of the form 1100011 (where 0 means "don't care"). However, some way of excluding wrap-around" squares would be needed, and there are complications in the recurrence relation for runs containing “don’t care” elements. |
|
|